
三大推理模型比較
o3-mini-high、Gemini 2.0 Flash Thinking、DeepSeek

我們都希望能給大模型一個簡要的任務,就能完成一連串複雜的工作任務,例如:撰寫市場研究報告、寫開箱體驗文。
從去年 9 月開始 OpenAI o1 開啟這一大模型的新篇章,12月 OpenAI 為期十二天的發佈會,發佈了 o3,Google 也稍稍推出 Gemini Deep Research (後為 Gemini-2.0-Thinking 系列模型)。進入 2025 年 1 月震撼中美 DeepSeek R1。僅接著 2月,OpenAI 緊急的再推出 o3-mini 系列的模型,以及擁有 o3 推理模型和較長時間計算時間的 Deep Research 功能。「推理模型」似乎又進來新的競爭時代,各家廠商有種我不趕緊釋出,下週或下個月可能模型就變廢物。但大模型在具備豐富知識後,又馬上具備有「推理」/「思考」的能力了嗎?
所以做了一些試驗,先總結下列要點,下面有章節也可以挑有興趣的看
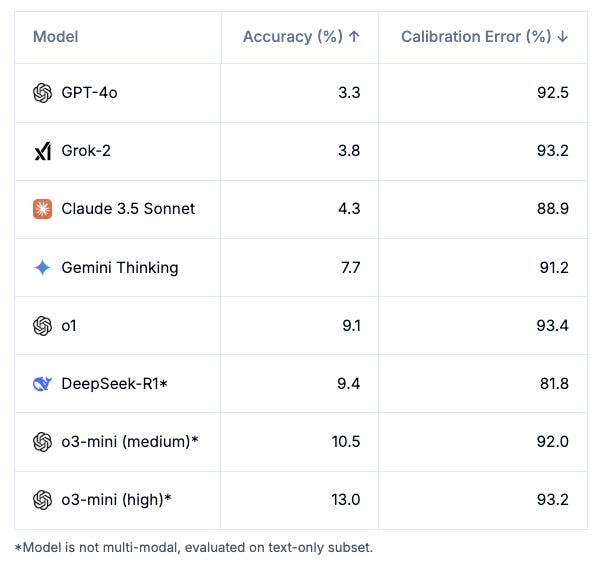
2025年就看推理能力競賽,三大推理模型在 HLE 評估仍只有 10 幾分而已(滿分100分)
o3-mini-high 回答問題的一致性最好,但不夠具體詳細。DeepSeek R1 和 Gemini-2.0-Thinking 回答的一致性還有段距離
Gemini-2.0-Thinking 很適合拿來學系統性的推理過程,DeepSeek R1 卻有點像是中國對話式的大型搜尋搜尋引擎,推理過程都是在說搜尋網頁的內容,OpenAI o3-mini-high 對你敷衍一下,有推理過程就好(感覺被送進LLM簡化過,再輸出給用戶)
三個模型的推理時間普遍都低於 30 秒,所以可能問題太大,會回答不好
模型能搜尋資料的能力,可能會很大影響答案的精準度。o3-mini-high 會顯示少量搜尋到的來源資料,但實際應該是參考更多;DeepSeek R1 主要就是搜尋中文的網路資料;Gemini-2.0-Flash-Thinking 應該是擁有最多資料的搜尋引擎,卻在推理的時候沒有顯示資料來源。但全部推理模型都不會直接搜尋論文網站,不知道什麼原因
用戶若對領域知識不熟悉,在驗證推理模型的輸出,會需要更大的努力。畢竟篇幅一長,需要校驗的地方多,會越來越難掌握產生幻覺的段落。人類對大模型的推理能力又比知識難理解,例如:商人和博士的思考邏輯和能力的差異,博士和一般上班族的思考能力的差異
章節
推理模型選擇
Prompt 問題
推理運行時間
思考過程比較
回答內容比較
限制
1. 推理模型選擇
從 Humanity Last Exam (HLE) 人類最後的考試的排名中,選出三間公司最高分的推理模型,並且在提問時,使用 Search 搜尋網路資料的功能。選出實驗的模型有:
OpenAI o3-mini-high
DeepSeek R1
Google Gemini-2.0-Flash-Thinking-Experimental with App
(Reasoning across Youtube, Maps & Search)
2. Prompt 問題
比較在 Deep Seek R1, ChatGPT o3, Gemini 2.0 Flash Thinking 三大模型訓練推理能力的強化學習方法會問這個問題是 DeepSeek R1 的論文[連結]中提到
採用了多階段的強化學習流程來培養模型的推理能力。最初,他們提出了一個叫 DeepSeek-R1-Zero 的模型,它從基礎模型出發,完全通過強化學習來“自發”發展推理能力。這裡,他們使用了 Group Relative Policy Optimization(GRPO)算法,並設計了特定的訓練模板,要求模型先生成包含詳細思考過程的 chain-of-thought(例如在〈think〉標籤內)再給出最終答案,同時利用基於規則的獎勵系統來鼓勵準確性和格式正確性。
不過,這種純 RL 方法(DeepSeek-R1-Zero)雖然能讓模型學到強大的推理策略,但生成內容往往可讀性不佳並且可能出現語言混雜。為了解決這些問題,論文進一步提出了 DeepSeek-R1:在進行強化學習前,先利用少量高質量的長 chain-of-thought 數據對基礎模型進行“冷啟動”微調,這樣可以讓模型輸出更加清晰和一致的思考過程。隨後,再用同樣的推理導向強化學習來進一步優化模型,並通過拒絕採樣和監督微調來最終精煉模型,使其在推理任務上達到接近 OpenAI-o1-1217 的水平
3. 推理運行時間
Jensen Huang 說「當 AI 思考時間越長,答案品質越高」
在這三個模型的實驗中,模型在推理所顯示的時間為
DeepSeek(25s) > Gemini-2.0-Flash-Thinking(7s) > o3-mini-high(5s)
相較於 OpenAI DeepResearch 的 5~30 分鐘,這三大模型的計算時間都算短!
模型 | 思考時間-回覆時間-總時間
ChatGPT o3-mini-high | 5s-47s-52s
DeepSeek R1 | 25s-100s-125s
Gemini-2.0-Flash-Thinking-Experimental | 7s-15s-22s
4. 思考過程比較
總結來說,這三個模型展現出不同的思考特點:
Gemini 展現最系統化的思考框架和自我修正能力
DeepSeek 在資訊處理和驗證上更為嚴謹
o3-mini-high 雖然簡潔但缺乏深入的分析過程
(本段採用 Claude 3.5 Sonnet 輔助分析三個模型的推理過程)
思考結構完整性:
Gemini: 展現最完整的系統思考,如其提出 "Break down '强化學習方法' and '訓練推理能力'" 的明確架構 (個人最喜歡的推理過程,很值得學習!)
DeepSeek: 重視資訊來源的系統整理,如 "需要综合这些信息,分点比较每个模型的强化学习方法"
o3-mini-high: 結構較簡單,缺乏深入分析過程
資訊處理方式:
DeepSeek: 最重視資訊來源確認,具體標註網頁編號。顯示搜尋到47個結果,來源都是簡體中文的網站為大部份,如:CSDN、知乎。
Gemini: 注重概念定義和框架建立,此次完全沒有列出搜尋的來源。
o3-mini-high: 較為直接但缺乏詳細驗證過程(看來 OpenAI 還是有留一手)。有顯示 4 個搜尋來源,分別是中國新浪、PTT、theverge,橫跨中英文都有了。
自我修正能力:
Gemini: 明確展現思考轉變過程,如從演算法比較轉向應用影響分析
DeepSeek: 在資訊整理過程中展現調整
o3-mini-high: 較少展現自我修正
詳細內容如下:
OpenAI o3-mini-high
The user asks about comparing the reinforcement learning methods for training and inference abilities of three models: Deep Seek R1, ChatGPT o3, and Gemini 2.0 Flash Thinking. I think they expect an analysis in Chinese. I need to translate the question to be more precise: "Comparison between reinforcement learning methods in training inference ability for three major models."
I should do a web search now, using the query: "Deep Seek R1 reinforcement learning training inference capability compare ChatGPT o3, Gemini 2.0 Flash Thinking". I'll gather info from this.
From my research, I see that DeepSeek R1 makes use of reinforcement learning (RL) techniques to focus on reasoning abilities, utilizing methods like "合成数据微调" and "多头潜在注意力 (MLA)". As for ChatGPT o3, it likely leverages RL with human feedback (RLHF) as its primary reinforcement method for improving reasoning skills. The Gemini 2.0 Flash Thinking by Google, though not explicitly using RL, trains the model by enhancing its reasoning through structured thinking steps, possibly incorporating RLHF or similar strategies for better performance.特點分析:
先確認問題本質並重新描述
規劃搜尋策略(雖然實際無法執行)
直接跳到結論而缺乏中間推理過程
DeepSeek R1
嗯,用户的问题是让我比较DeepSeek R1、ChatGPT o3和Gemini 2.0 Flash Thinking这三个模型在训练和推理能力方面使用的强化学习方法。我需要先看看搜索结果里的各个网页内容,找出相关的信息。
首先,网页1提到了DeepSeek专注于效率和可扩展性,可能采用轻量级架构,而ChatGPT基于GPT架构,缺乏多模态能力,Gemini是多模态的。不过这里可能更多是总体对比,不太涉及具体的强化学习方法。网页2则详细比较了Gemini 2.0 Flash和DeepSeek R1,在准确度、成本、速度方面,但可能没有具体讲强化学习的技术细节。网页4对比了R1和o1,但用户的问题是关于o3,可能不太相关。网页5提到Gemini 2.0 Flash Thinking和ChatGPT o1及DeepSeek R1 Lite的对比,其中提到推理扩展技术,比如测试时计算,让模型在推理时多思考,这可能涉及到强化学习中的推理步骤优化。网页6中李广密的文章指出DeepSeek R1推进了强化学习和推理模型范式,可能使用了RL和知识蒸馏的方法。网页9的终极对决里详细比较了四个模型的推理能力,其中提到DeepSeek R1的meta-cognition和probabilistic inference,这可能和强化学习有关。网页10提到Gemini 2.0系列的性能提升,可能涉及新的训练方法。
现在需要整理每个模型的强化学习方法。比如,DeepSeek R1在网页1、6、9中提到使用知识蒸馏、强化学习(RL)和推理时的思考过程,可能结合了CoT(思维链)透明化。ChatGPT o3在网页9中提到了chain-of-thought reasoning,可能使用分阶段的强化学习优化。而Gemini 2.0 Flash Thinking在网页2、5、7中强调速度和实时数据处理,可能通过轻量级架构和高效推理优化,但具体强化学习方法可能较少,更注重多模态处理。
需要注意各个模型的技术特点:比如DeepSeek R1的RL与知识蒸馏结合,ChatGPT o3的链式思维推理,Gemini的实时推理和测试时计算。还需要引用对应的网页编号,比如网页6提到DeepSeek通过RL和test-time compute推进行业范式,网页5提到Gemini和o1的测试时计算,网页9提到各个模型的推理能力细节。需要综合这些信息,分点比较每个模型的强化学习方法,并引用对应的搜索结果。特點分析:
系統性評估每個資訊來源
明確標註資訊來源編號
分層次組織資訊
注重資訊可驗證性
Gemini 2.0 Flash Thinking
The user is asking for a comparison of reinforcement learning methods for training and inference capabilities in three large models: Deep Seek R1, ChatGPT o3, and Gemini 2.0 Flash Thinking.
To answer this, I need to:
Identify the core of the question: It's about comparing reinforcement learning (RL) techniques used for training and inference in these models. "强化學習方法" (reinforcement learning methods) and "訓練推理能力" (training and inference capabilities) are the key phrases.
Consider the models: Deep Seek R1, ChatGPT o3, and Gemini 2.0 Flash Thinking. These are all large language models (LLMs), but their architectures and specific training methodologies might differ. "Flash Thinking" in Gemini 2.0 hints at a specific inference optimization strategy.
Break down "强化學習方法" and "訓練推理能力":
强化學習方法 (Reinforcement Learning Methods): In the context of LLMs, this often refers to techniques like:
RLHF (Reinforcement Learning from Human Feedback): Using human feedback to fine-tune the model's outputs to align with human preferences (e.g., helpfulness, harmlessness, truthfulness).
Self-play RL: Models play against themselves to improve strategic decision-making or generate more diverse outputs.
Other RL algorithms: Potentially PPO (Proximal Policy Optimization), or other on-policy/off-policy methods.
訓練推理能力 (Training and Inference Capabilities):
Training: How RL is integrated into the training process to enhance specific abilities.
Inference: How RL, or training using RL, impacts the model's inference-time performance, especially regarding reasoning, decision-making, and output quality.
Research and gather information: I need to access information about the training and inference techniques used in these models. This might involve looking at research papers, blog posts, articles, and official model documentation (if available). It's important to note that specific details of training are often proprietary, so publicly available information might be general or high-level.
Structure the comparison: A table or structured format is likely best for comparing the three models across different dimensions. The dimensions could be:
RL method used: (RLHF, self-play, etc.)
Purpose of RL: (alignment, reasoning, output quality, etc.)
Impact on Training: (how RL enhances the training process)
Impact on Inference: (how RL affects inference performance and capabilities)
Specific features/techniques: (e.g., "Flash Thinking" in Gemini 2.0)
Draft the comparison: Based on the gathered information, fill in the table/structure. Acknowledge any information gaps or uncertainties. Highlight any unique aspects of each model's approach.
Refine and enhance:
Clarity and Accuracy: Ensure the comparison is clear, accurate, and avoids making unsupported claims.
Comprehensiveness: Cover all relevant aspects of RL and training/inference capabilities.
Use of Chinese (Traditional): Ensure proper use of terminology and grammar.
Include Image Suggestion: Think about whether images would be helpful to illustrate any concepts. (In this case, maybe not essential for a direct comparison table, but conceptually images of RL loops or model architectures could be used in a more general explanation of RL in LLMs, if the prompt was more general.)
Self-Correction/Refinement during the process:
Initial thought: Maybe directly comparing the algorithms used by each model.
Correction: Algorithms themselves are less important than the application and purpose of RL in each context. Focus on what RL is used for and how it impacts training and inference capabilities, rather than just listing algorithm names which might be unknown or less informative at a high level.
Realization: Detailed technical specifications might be unavailable for all models. Focus on publicly available information and infer based on general knowledge about LLM training.
Final Structure Choice: Table comparing models across key aspects will be the clearest and most informative format for direct comparison.
By following these steps, I can create a comprehensive and informative comparison that addresses the user's request.特點分析:
建立明確的問題分析框架
詳細定義關鍵概念
展現自我修正過程
系統化規劃回答步驟
5. 回答內容比較
在這個題目下,想看的是:
一致性:回答內容跟問題是不是一致、相關
正確性:回答的內容是否正確
具體性:具體詳細的介紹、比較不同推理模型之間,在訓練推理能力上的強化學習差異
總的來說,個人的評分是
一致性:o3-mini-high > Gemini-2.0-Flash-Thinking > DeepSeek R1
正確性:o3-mini-high > DeepSeek R1, Gemini-2.0-Flash-Thinking
具體性:都不足(可能受計算時間不夠長的影響)
雖然不是很滿意,但也從每個模型產生的內容,有一些觀察
ChatGPT o3-mini-high [內容]
回答的最靠近我的問題。例如:DeepSeek R1 的一大創新在於它不依賴傳統的監督式微調(SFT),而是直接利用強化學習(RL)來進行後訓練,專注於提升推理能力。在具體性上,稍顯不足,並沒有提到 DeepSeek 論文中 說的 Group Relative Policy Optimization (GRPO) 或避免獎勵黑客(Reward Hacking)。DeepSeek R1
回答很多專業技術的內容,但跟我的問題相關性低,例如:響應速度、高容量上下文Gemini 2.0 Flash-Thinking [連結]
一樣沒有回答在問題上,並且產生的結果,正確性有明顯的不足,例如:關於 DeepSeek R1 的公開技術細節相對較少。DeepSeek 相較於 ChatGPT 和 Gemini 公開最多細節的
6. 限制
Prompt 下繁體中文,有可能下英文,在搜尋資料的幅度會更廣,正確性可能也會更高
模型在搜尋資料時,受限於 Prompt 為繁體中文,所以能搜尋到的相關資料較少
介面上顯示的推理時間,可能不見得是分配的算力或使用的時間
多種問題或多做幾次實驗,推理模型能力的評估,可能會更好、精準